保温杯怎么选品?我用 亚马逊评论采集 抓了 5 个竞品的差评,挖出 3 个差异化机会
选品做到第三步,市场也判断了,细分赛道也圈出来了,下一个绕不过去的问题:我做的保温杯,凭什么比已经在 BSR 上的那些卖得好?
这个问题不能拍脑袋,必须从一个地方挖答案——竞品的差评。差评是用户花钱后写的真实抱怨,是市面上现有产品最薄弱的位置,也是你切进去的差异化机会。
这一步到底在解决什么问题
"挖差评"听起来很玄学,但其实就在回答 3 个问题:
- ① 现在卖得好的保温杯,用户最常抱怨什么?
- ② 这些抱怨里,哪些是产品设计能解决的,哪些是用户预期问题?
- ③ 我做的保温杯,能不能针对其中 1-2 个痛点做改进,让 listing 上写出"我们解决了 XX"这种钩子?
为什么我不再手动翻评论
3 年前我也是手动干的。打开 Amazon 竞品页,按"最近"或"差评优先"筛选,一条条往下滑,看到说漏水的就贴一条到 Excel,说保温差的贴另一行……
❌ 手动翻评论 5 个 ASIN 全套流程
· 每个竞品翻 50-100 条
· 5 个竞品 = 一晚上没了
· 贴到 Excel 里全是文本,看不出占比
· 第二天看回去,标错的、漏掉的一大堆
· 心里没底,不敢拍板
✅ 用 EasyClaw 「亚马逊评论采集」 skill
· 1 条自然语言指令
· 5 个 ASIN 同时并行抓
· 每个抓 10 条样本,快速摸底
· 结构化数据输出:评分/标题/正文/时间/类型
· 总耗时 2-3 分钟(取决于反爬延迟)
为什么我不用纯爬虫工具,要用 EasyClaw
市面上做"评论采集"的工具不少(Helium 10 / JungleScout 都有类似功能)。但我用了一年下来,爬虫只解决一半问题,另一半才是关键:
🛠️ 纯爬虫工具
抓完评论 → 给你一份 JSON / CSV
→ 剩下的"读懂数据",得你自己来
新手最大的痛点:拿到一堆评论,怎么归类?高分竞品几乎没差评,机会到底在哪?隐性痛点怎么挖?
→ 又要花一晚上手动分析,本质上没解决问题。
🤖 EasyClaw =「skill 抓数据 + 大模型分析」组合
「亚马逊评论采集」skill 负责抓回原始 JSON
→ EasyClaw 主体大模型接管这份 JSON 自己分析
→ 直接告诉你:哪条差评最关键、4-5 星好评里藏着哪些隐性痛点、哪些痛点横跨多个竞品…
这才是 EasyClaw 真正区别于爬虫的地方——不只给你数据,还告诉你数据意味着什么。
我是这么让 EasyClaw 干这活的
具体动作分两步:先装 skill,再发指令。
📦 「亚马逊评论采集」
真实能力:调用 EasyClaw 本地内核,自动开浏览器翻页采集亚马逊商品评论,输出结构化数据。每条评论返回评分/评论人/标题/时间地点/详情/类型 6 个字段,可选图片URL/视频URL。内置 3-8 秒随机延迟反爬。
帮我用 亚马逊评论采集 抓这 5 个保温杯 ASIN 各 10 条评论,重点要 1-3 星差评。
EasyClaw 会自动把 ASIN 转成评论页 URL(带 reviewerType=all_reviews 参数),并行调浏览器内核抓取。
skill 抓回来的是什么
跑完之后,亚马逊评论采集 给我返回了每个 ASIN 的结构化评论数据,每条带 评分、评论人、标题、时间地点、正文、评论类型 6 个字段(可选图片/视频 URL)。skill 只负责"抓数据",严禁编造——抓不到就报错。
但原始数据是死的,真正值钱的是下一步:让 EasyClaw 把这些评论读懂、归类、从好评里挖出隐性痛点。
EasyClaw 接管这份数据后,自己做了归类分析
我跟 EasyClaw 接着说:
EasyClaw 主体 LLM(不依赖任何额外 skill)拿这份数据做了二次分析,输出归类报告。结果出乎意料——这 5 个竞品评分都在 4.4-4.7 之间,几乎没有差评:
| ASIN | 商品 | ★评分 | 总评数 | 1-3 星差评 |
|---|---|---|---|---|
B0GJS619G5 | Konokyo FLOWPLAY Push-Button 18oz | 4.7 | 35 | 0 |
B0F6C5GQ4T | KEWIXY Cherry Water Bottle 18oz | 4.5 | 153 | 0 |
B0FF9MMXM6 | Halloween Tumbler 40oz | 4.4 | 182 | 1 条 (3★) |
B0G4CDM3QN | Dog Affirmation Tumbler 40oz | 4.6 | 526 | 0 |
B0GKQYGY2J | BrüMate Era Flip 30oz | 4.5 | 530 | 0 |
唯一的那条差评(B0FF9MMXM6 · 3 星)
"吸管一直从盖子上脱落进杯子里,很恶心。保冷还行,但吸管问题太烦人了。"
更值钱的是——EasyClaw 还从 4-5 星好评里挖出了一批用户"边夸边吐槽"的隐性痛点,并按占比归类、给出切入建议:
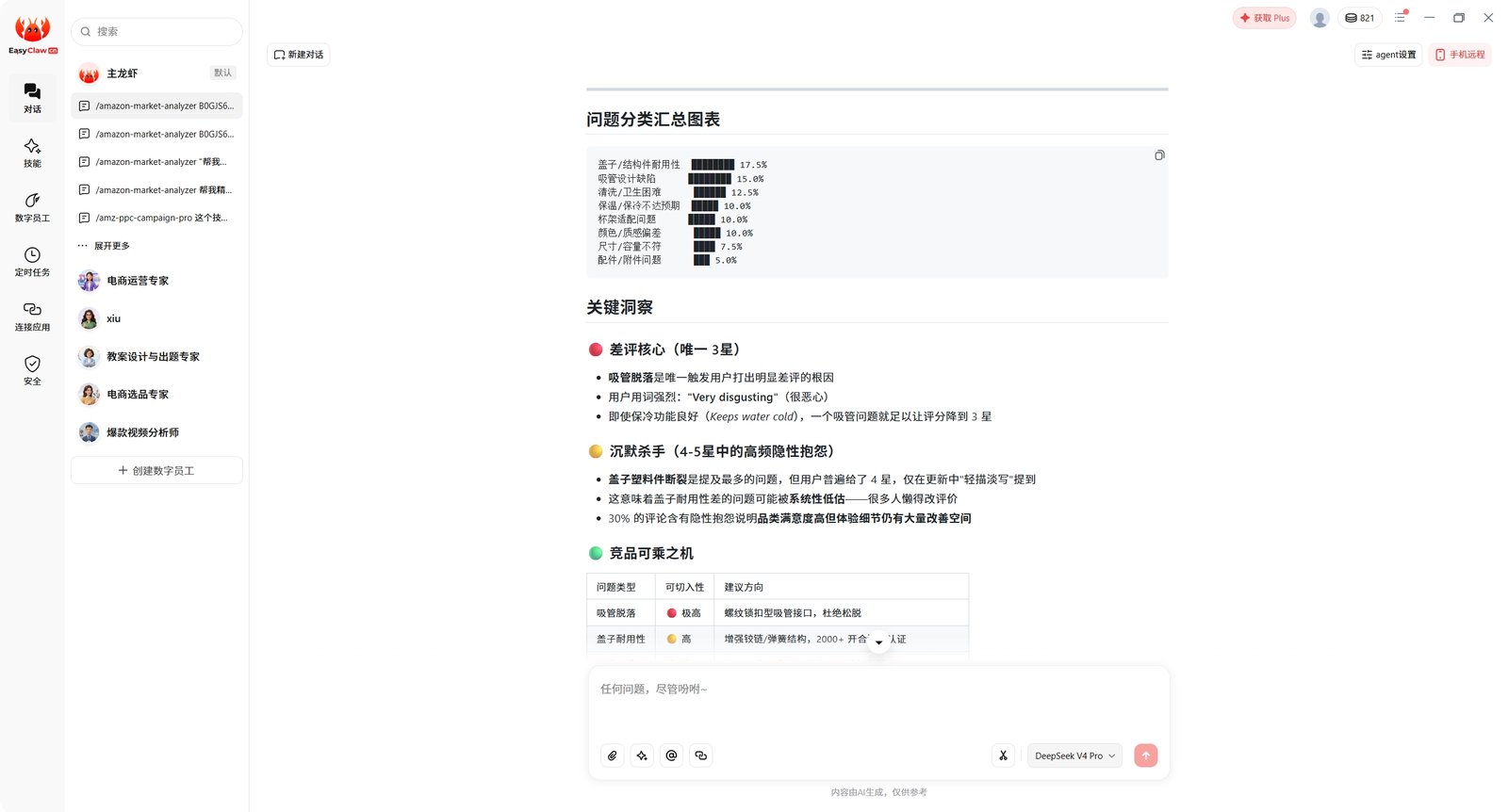
下面是这份报告的文字版本(方便引用和搜索引擎索引)。先看 8 类问题的占比分布:
| 问题类型 | 占比 | 严重度 |
|---|---|---|
| 盖子 / 结构件耐用性 | 17.5% | 高 |
| 吸管设计缺陷 | 15.0% | 高 |
| 清洗 / 卫生困难 | 12.5% | 中 |
| 保温 / 保冷不达预期 | 10.0% | 中 |
| 吸嘴异味 | 10.0% | 中 |
| 颜色 / 质感偏差 | 10.0% | 低 |
| 尺寸 / 容量不符 | 7.5% | 低 |
| 配件 / 附件问题 | 5.0% | 低 |
再看 EasyClaw 给出的 三层关键洞察——这才是它区别于纯爬虫的地方:
🔴 差评核心(唯一的 3 星)
- 吸管脱落是唯一能让用户打出明显差评的原因
- 用户用词强烈:"Very disgusting"(很恶心)
- 即使保温功能良好(Keeps water cold),一个吸管问题就足以让评分降到 3 星
🟡 沉默杀手(4-5 星里的高频隐性抱怨)
- 盖子塑料件断裂是提及最多的问题,但用户普遍给了 4 星,仅在评论里"轻描淡写"提到
- 这意味着盖子耐用性差的问题可能被系统性低估——很多人懒得改评价
- 30% 的评论含隐性抱怨,说明品类满意度高,但体验细节仍有大量改善空间
🟢 竞品可乘之机(切入建议)
| 问题类型 | 可切入性 | 建议方向 |
|---|---|---|
| 吸管脱落 | 极高 | 螺纹锁扣型吸管接口,杜绝松脱 |
| 盖子耐用性 | 高 | 增强铰链 / 弹簧结构,做 2000+ 次开合认证 |
关键来了:这份表怎么读出"机会"
高分赛道,机会藏在好评的"边夸边骂"里
这 5 个竞品评分 4.4-4.7、几乎零差评——新手会判断"没机会"。但 "吸管不防漏/漏液"在 4-5 星好评里被提了 3 次,涉及 2 个 ASIN。用户愿意打 5 星但仍忍不住吐槽,说明这是个"忍着用"的真实痛点——正是切入点。
看痛点交叉覆盖几个竞品
"吸管漏液"和"盖子塑料件断裂"各自都横跨 2 个以上 ASIN——这说明不是单一产品的偶发问题,而是整个细分赛道的通病。赛道级通病比单品缺陷价值大得多:你解决了它,就对整个赛道形成差异化,而不只是赢一个竞品。
看用户原话,反推卖点钩子
那条唯一差评的原话是"吸管一直从盖子上脱落进杯子里"——用户能精确描述"吸管脱落"这个动作,说明他们对吸管结构有感知。我未来 listing 的钩子就有了:"Secure Lock Straw — Never Falls In"。这种基于真实用户语言反推的卖点,比"高品质保温杯"这种泛词强 10 倍。
三个信号叠加在一起,我得出本轮选品的差异化结论:
🎯 切入点 = 解决"吸管脱落/漏液 + 盖子塑料件不牢"这两个赛道级通病。
钩子 = 防脱落锁扣吸管设计 + 加固盖体卡扣 + 防漏密封结构。
同样这份数据,两种卖家的决策完全不同
到这一步,"挖出差异化机会"就完成了。但接下来怎么用这份机会,精品 FBA 和无货源走的是完全不同的路。
把隐性痛点变成产品改造方案
带着这份"吸管漏液 3 次 / 盖子断裂 2 次"的数据去找 1688 工厂,明确告诉他们:"我要防脱落锁扣吸管,盖子卡扣要做加固,要过跌落+密封双重测试"。打样 3-5 款实测,定稿后做品牌私模。
下一步动作:带着差异化卖点 → 1688 找工厂打样 → 实测对比竞品 → 定稿
把隐性痛点当作选款的"否定清单"
不能改产品,但能选不踩雷的款。直接在 1688 找货时,把"吸管易脱落""盖子塑料薄""漏液"这些词作为排除项,只挑评分 4.6+、买家秀里能看到吸管锁扣结构、盖体厚实的款。
下一步动作:用隐性痛点反向 → 1688 找货时筛选 → 选择口碑稳的现货款铺货
老 K 的避坑笔记
这 4 个坑我自己都踩过,新手别再走一遍
- 只看 1-3 星差评:这次 5 个竞品差评几乎为 0,只看差评的人会直接放弃。真正的金矿在 4-5 星好评的"边夸边吐槽"里——让 EasyClaw 把好评也一起抓回来分析隐性痛点。
- 把单品缺陷当赛道机会:只在一个 ASIN 出现一次的问题可能是偶发。要看痛点是否横跨多个竞品——跨 2 个以上 ASIN 的才是赛道级通病,值得做差异化。
- 不看用户原话:归类标签("漏液")是抽象的,用户原话("吸管一直从盖子上脱落进杯子里")才有产品设计指向性。listing 钩子要从原话里提炼。
- 把所有吐槽都当机会:"颜色和图片有色差""发货慢"这种属于预期管理问题而非产品缺陷,改产品也解决不了。只挑能从设计/工艺层面改进的痛点。